| Tags: |
|---|
Shallow Parsing with Conditional Random Fields
This paper describes an implementation of a chunker using IOB encoding with a CRF.
The following table lists the features used in the chunker:
| Feature | Description |
|---|---|
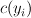 |
The current output tag. |
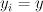 |
The current state (current and previous output tag). |
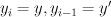 |
A tuple of the current state and the previous state (current and previous two output tags). |
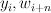 |
A tuple of the current state and the 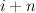 th word, th word,
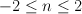 . . |
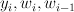 |
A tuple of the current state, the current word, and the previous word. |
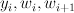 |
A tuple of the current state, the current word, and the next word. |
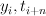 |
A tuple of the current state and the part of speech tag
of the th word, . |
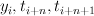 |
A tuple of the current state and the two consecutive part
of speech tags starting at word , 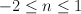 . . |
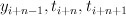 |
A tuple of the current state, and three consecutive part
of speech tags centered on word , 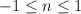 . . |
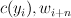 |
A tuple of the current output tag and the th word,
. |
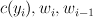 |
A tuple of the current output tag, the current word, and the previous word. |
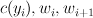 |
A tuple of the current output tag, the current word, and the next word. |
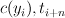 |
A tuple of the current output tag and the part of speech
tag of the th word, . |
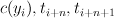 |
A tuple of the current output tag and the two consecutive
part of speech tags starting at word ,
. |
|
A tuple of the current output tag, and three consecutive
part of speech tags centered on word ,
. |