| Tags: |
|---|
Accurate Unlexicalized Parsing
Although the introduction of lexico-structural dependencies are clearly very important to the performance of advanced lexicalized parsers, they are by no means the only reason that these parsers out-perform naive PCFG parsers. In order to explore which non-lexical dependencies are important to improving parser performance, Klein & Manning applied a manual hill-climbing approach to develop a sequence of tree transformations that improve upon the performance of a baseline PCFG system. Using this method, they find a sequence of 17 transformations that increases the performance of their unlexicalized parser to a level comparable to that of basic lexicalized parsers.
Their baseline system differs from a simple PCFG in that it begins by decomposing all nodes with a branching factor greater than 2 into binary branching nodes. This binary branching decomposition is centered on the head node; and new node labels are created for the intermediate nodes. These new node labels, which Klein & Manning refer to as "intermediate symbols," initially consist of the original node label plus the part of speech of the head word; but they may be modified by transformation operations, as described below.
All of Klein & Manning's transformations consist of splitting select
node labels into two or more specialized labels. The first two
transformations relax the conditional independence assumptions of the
simple PCFG model by adding contextual information about a node's
parents or siblings to that node's label. The first of these
transformations, vertical-markovization(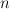 ), augments each
non-intermediate node label with the labels of its closest
ancestor nodes. This is essentially a generalization of Mark
Johnson's parent transformation. The second transformation,
horizontal-markovization(), is analogous, except that it
applies to intermediate nodes, and thus adds information about
siblings instead of ancestors. Klein & Manning also consider a
variant of these transformations which does not split intermediate
states that occur 10 or fewer times in the training corpus. For their
overall system, they settle on a value of
), augments each
non-intermediate node label with the labels of its closest
ancestor nodes. This is essentially a generalization of Mark
Johnson's parent transformation. The second transformation,
horizontal-markovization(), is analogous, except that it
applies to intermediate nodes, and thus adds information about
siblings instead of ancestors. Klein & Manning also consider a
variant of these transformations which does not split intermediate
states that occur 10 or fewer times in the training corpus. For their
overall system, they settle on a value of 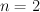 for both Markovization
transformations.
for both Markovization
transformations.
Klein & Manning describe fifteen additional transformations, which
split node labels based on a variety of contextual features, including
both "internal context" (features of the phrase itself) and
"external context" (features of the tree outside the phrase).
Individually, these transformations improve 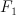 performance by
between 0.17% and 2.52%; in total, performance is improved by 14.4%,
from 72.62% to 87.04%.
performance by
between 0.17% and 2.52%; in total, performance is improved by 14.4%,
from 72.62% to 87.04%.