| Link: | webpage |
|---|
SemEval 2007 Workshop
random thought.. pick some verbs, or vn verb classes, and use google searches over large numbers of nouns, to try to figure out features such as animacy.. e.g., if X is volitional then we expect to see "X wants", "X thinks", etc.
Invited Talks & Panels
The OntoNotes Project (Eduard Hovy)
Ed went over the ontonotes project, & talked about the importance of treating annotation science as an object of study. Showed some of the tools used in ontonotes, esp for tracking, and talked about why they're important.
Panel: Inference with semantics: tasks and applications
Tasks
SemEval-2007 Task 01: Evaluating WSD on Cross-Language Information Retrieval
Eneko Agirre, Bernardo Magnini, Oier Lopez de Lacalle, Arantxa Otegi, German Rigau and Piek Vossen
Testing whether WSD can help out with cross language IR
first stage:
- wsd algorithm open
- IR system fixed
Data:
- Corpus: 170k English documents, 580 Mb text.
- Limit to 16% of the corpus. 201 topics.
Users must:
- perform WSD on the documents & queries, using WordNet 1.6 senses
SemEval-2007 Task 02: Evaluating Word Sense Induction and Discrimination Systems
Eneko Agirre and Aitor Soroa
Evalutate unsupervised WSD systems.
Two evaluations:
- unsupervised evaluation
- indicued senses are treated as clusters
- gold standard senses treated as clusters
- compare clusterings using "FScore" (as if each cluster was the result of a
query). Note, it appears that FScore
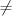 f-measure.
f-measure.
- supervised evaluation
- split corpus into two: train/test
- learn mapping to gold standard
- use standard precision/recall
evaluation is tricky. different evaluations introduce different biases. e.g., unsupervised eval prefers small clusters; supervised prefers most-frequent-sense.
SemEval-2007 Task 04: Classification of Semantic Relations between Nominals
Roxana Girju, Preslav Nakov, Vivi Nastase, Stan Szpakowicz, Peter Turney and Deniz Yuret
Given a word pair, disambiguate the relationship between those word pairs. It's been considered for a long time, but there's still no agreed-upon inventory of relationship types.
Compared to PropBank: it's not clear when two relationships between two words are "the same" -- relations are defined with respect to specific lexical items.
Also, focus is on noun-noun relations.
Given a word pair and a syntactic context, decide what relation is encoded. cf. to WSD, where we're given one word and its context.
Not just looking at adjacent words.
7 relations were chosen:
- cause-effect
- instrument-agency
- produce-product
- origin-entity
- theme-tool
- part-whole
- content-container
relations are defined explicitly -- specify whether it can be metaphorical, abstract, etc. include restrictions, notes, positive examples, near-miss examples.
Examples were found using pattern searches w/ google.
Conclusions:
- wordnet helps
- using query doesn't help (here, "query" refers to the google search patterns that were used to create the corpus)
- more training data is better
SemEval-2007 Task 07: Coarse-Grained English All-Words Task
Roberto Navigli, Kenneth C. Litkowski and Orin Hargraves
Fine grained WSD (a la WordNet) gives low interannotator agreement -> not useful to systems.
So improve performance by using more coarse grained senses
5k words. content words annotated. 2.25k words annotated.
Deciding on a sense inventory is difficult. Try mapping to an existing sense inventory (Oxford English Dictionary). Any senses that did not map to an OED sense remained as separate senses.
average polysymy: 6 fine-grained, 3 coarse-grained.
interannotator agreement
- for the sense mapping: 86.44
- for the sense annotation: 93.8%
most frequent sense: 78.9%. best systems: ~82.5%.
University of Rochester system does unusually well on one of the documents (a CS document), which gives it a high overall score. Other than that document, it's more in line with the other systems.
SemEval-2007 Task 08: Metonymy Resolution at SemEval-2007
Katja Markert and Malvina Nissim
metonymy: use expression to refer to a related one; but without equating them or asserting that they're similar.
categorize patterns. e.g.: org-for-members; org-for-product; org-for-facility; org-for-event
collocation features aren't enough. syntactic features help.
SemEval-2007 Task 10: English Lexical Substitution Task
Diana McCarthy and Roberto Navigli
Evaluate WSD, with potential impact. Sense inventory not hand-picked.
Task: find a replacement word for a taret word in a context.
200 words; 10 words for each sentence. Data = 30 of the words. Sentences picked semiautomatically
5 humans annotated the data set w/ substitutes. Instructions for annotators: Using dictionary or thesaurus is ok. Providing 0, or more than 1, is ok. Phrases are ok if you can't think of a word.
SemEval-2007 Task 11: English Lexical Sample Task via English-Chinese Parallel Text
Hwee Tou Ng and Yee Seng Chan
training data obtained semi-automatically from parallel tasks.
For WSD, it's hard to get enough sense tagged data. so use parallel tasks to generate training data for WSD, based on how a word gets translated.
SemEval-2007 Task 13: WePS Evaluation: Establishing a benchmark for the Web People Search Task
Javier Artiles, Julio Gonzalo and Satoshi Sekine
how is it different from WSD:
- unknown number of "senses"
- highter avg ambiguity
- boundaries between "senses" are stronger
- document might refer to different people w/ the same name (c.f. multiclass problem)
different souces for names: wikipedia, US census, CS conferences. test data set had much higher ambiguity than training data set.
SemEval-2007 Task 14: Affective Text
Carlo Strapparava and Rada Mihalcea
Classify emotion and polarity (positive/negative) associated with a short text. Why do we care? Sentiment analysis for opinion mining; computer-assisted creativity; verbal expressivity in HCI
Corpus: headlines from different news sites. 250 headlines in dev set, 1k annotated headines in test set. Eg:
- Thailand attack kills three, injures 70.
Two tasks: - Predict emotional labels: anger, disgust, fear, joy, sadness, surprise. (each label gets a value 0-100) - Predict polarity: positive, negative. (actually, -100 to 100)
Unsupervised task; but participants may use any data they want. Extra data provided: words extracted from wordnet-affect; and links to other resources such as SentiWordNet.
ITA seems low to me (but then I'd expect it to be low -- deciding how angry a headline is seems very subjective).
SemEval-2007 Task 15: TempEval Temporal Relation Identification
Marc Verhagen, Robert Gaizauskas, Frank Schilder, Mark Hepple, Graham Katz and James Pustejovsky
How do we evaluate temporal relations? Temporal links are not independent from one another -- there are dependencies between relations. It's possible to have two temporal relation graphs which are different, but equivelent semantically. One solution: use temporal closures. But then how do we decide how different two graphs are when they differ from one another? We want to compare graphs, not instances (links, etc).
So, split the task into smaller parts, and evaluate on those smaller tasks. Chosen appropriately, allows simple pairwise comparison. 3 tasks.
Data: timebank (timeML) tlinks.
Output values:
- before, after, overlap
- Also try relaxed scoring, including: before-or-overlap, overlap-or-after, vague
Tasks:
- Task A: given a time expression and an event expression, say how they relate to one another.
- Task B: given an event expression, say how it relates to the document creation time.
- Task C: given two sentences, say how their main events relate.
Future work: more data; and more (specific) tasks.
SemEval-2007 Task-17: English Lexical Sample, SRL and All Words
Sameer Pradhan, Edward Loper, Dmitriy Dligach and Martha Palmer
(my talk)
compare delta wrt to the baseline for that year -- baseline went down so not surprising that performance went down.
lexical sample task -- why are some senses ontonotes senses but some are grouped wn senses?
Systems
UIUC: A Knowledge-rich Approach to Identifying Semantic Relations between Nominals
Brandon Beamer, Suma Bhat, Brant Chee, Andrew Fister, Alla Rozovskaya and Roxana Girju
- syntactic contexts encode (or have preferences over) semantic relations
- use rich semantic features
- core features: morpho-lexical-semantic info from target nouns
- context features: sentence context
- sepcial features: specific features related to semantic relations
FBK-IRST: Kernel Methods for Semantic Relation Extraction
Claudio Giuliano, Alberto Lavelli, Daniele Pighin and Lorenza Romano
PSNUS: Web People Name Disambiguation by Simple Clustering with Rich Features
Ergin Elmacioglu, Yee Fan Tan, Su Yan, Min-Yen Kan and Dongwon Lee
CLaC and CLaC-NB: Knowledge-based and corpus-based approaches to sentiment tagging
Alina Andreevskaia and Sabine Bergler
2 systems: one knowledge-based and unsupervised; and one corpus-based and supervised.
knowledge-based: assigns sentiment to WN entries; and use the words in a headline to try to predict its polarity. complemented w/ syntactic info & valence shifters. Gets high precision and low recall. Why low recall? Because the headlines are so short; and because there's no semantic info for proper names, which are good cues for human annotators.
supervised: naive bayes corpus based approach. manually annotated data (1100 examples total -- 400 positive, 400 negative, 300 neutral). features = unigrams. (annotated data was tagged as -100, 0, or 100 only -- not fine-grained). recall is high, but precision is lower. challenges include: low amount of training data, multiplicity of domains.
WVALI: Temporal Relation Identification by Syntactico-Semantic Analysis
Georgiana Puscasu
seemed fairly interesting.
I2R: Three Systems for Word Sense Discrimination, Chinese Word Sense Disambiguation, and English Word Sense Disambiguation
Zheng-Yu Niu, Dong-Hong Ji and Chew-Lim Tan
NUS-PT: Exploiting Parallel Texts for Word Sense Disambiguation in the English All-Words Tasks
Yee Seng Chan, Hwee Tou Ng and Zhi Zhong
UNT: SubFinder: Combining Knowledge Sources for Automatic Lexical Substitution
Samer Hassan, Andras Csomai, Carmen Banea, Ravi Sinha and Rada Mihalcea