| Presenter: | Koby Crammer |
|---|---|
| Slides: | Powerpoint |
Advanced Online Learning for Natural Language Processing (Tutorial)
Online learning: incrementally train a classifier (or other model) based on a stream of training examples
distinguish between the classifier and the training algorithm
in some cases, treat teacher as adversary -- tries to stump the 'student'
Notation
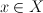
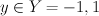
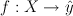
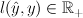
discrete prediction:
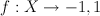
continuous prediction:
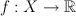
- Think of the sign as the label
- Think of the abs value as the confidence
Loss functions
- zero-one loss: 1 iff the answer is correct
- hinge loss:
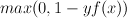 -- i.e., if the answer is right, then 0; otherwise, the magnitude of f(x).
-- i.e., if the answer is right, then 0; otherwise, the magnitude of f(x). - exponential loss
- log loss
- etc.
Framework
- initialize classifier
- for each round t
- recieve input instance
- output prediciton
- get feedback
- compute loss
- update prediction rule
goal:
- minimize cumulative loss
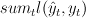
Linear classifiers
Define features and weights:
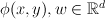
constrain: 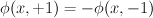
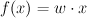
prediction: 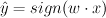
(Discussion of SVM-type stuff -- margins, etc.)
Why online learing?
- Fast
- Memory efficient - process one example at a time
- Simple to implement
- Formal guarantees – Mistake bounds
- Online to Batch conversions
- No statistical assumptions
- Adaptive
- but.. Not as good as a well designed batch algorithms
Update rules: we want an algorithm that maps 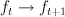 .
.
Using a weight-based model, we're mapping from 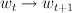
(discussion of some simple update rules -- perceptron, etc)
Perceptron is basically minimizing the zero-one loss; but we can design variants that minimize other loss functions.
Problems with perceptron:
- Margin of examples is ignored by update
- Same update for separable case and inseparable case
Passive-Agressive Approach
- minimize a loss function (maximize margin)
- basic algorithm does not work in inseperable case
- Enforce a minimal non-zero margin after the update (cf perceptron, which does not guarantee margin after approach)
- In particular :
- If the
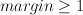 , then do nothing
, then do nothing - If the
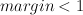 , update such that the margin after the update is enforced to be 1.
, update such that the margin after the update is enforced to be 1.
- If the
Define a dual space, to be the space of weight vectors. I.e., a given point in this "version space" identifies a single classifier.
For a given training sample, we can determine the subspace of this dual space that will classify it correctly. I.e., the set of all models that get that sample correct will be in that region. (We can enforce a margin of 1 by finding the subspace of this dual space that identifies the sample correctly with a margin of at least one.)
So we start with a point 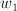 in the version space. Then, for each new training sample, we find the line $`1 le y_t(w_t cdot x_t$`, which seperates the space into classifier models that classify the training sample with an acceptable margin, and those that don't. For each new training sample, we project
in the version space. Then, for each new training sample, we find the line $`1 le y_t(w_t cdot x_t$`, which seperates the space into classifier models that classify the training sample with an acceptable margin, and those that don't. For each new training sample, we project 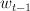 onto this line.
onto this line.
Agressive step update:
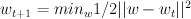 such that
such that 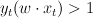
This can be solved analytically. If the constraint is already satisfied, then the solution is trivial: stay where we are. If the constraint is not satisfied, then we choose the closest point that does satisfy it. I.e., make the minimal change to the model that will allow us to get the right solution with an acceptable margin.
Comparing PA with perceptron: in both cases we have: 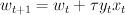 . For the perceptron,
. For the perceptron,  is basically the zero-one loss function. For the PA, is proportional to the hinge loss function (it's scaled by
is basically the zero-one loss function. For the PA, is proportional to the hinge loss function (it's scaled by 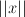 ).
).
So there appears to be a tight connection between the algorithm update and the loss function we're optimizing on.
Unseperable case
Modify -- i.e., rather than projecting all the way to the part of the model space that gets the new example right, just project 'part way' there:
 such that
such that 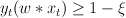 ,
, 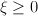
Two ways we can go with this:
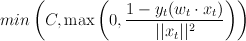
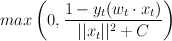
Relation to SVMs
This will basically converge to the same thing as SVMs if we re-iterate the examples repeatedly -- i.e., if we have memory.
Complex Learning Tasks
- binary classification
- n-way classification, no ordering or relation
- n-way classification, ordered (eg rate movies 1-5)
- n-way classification, hierarchical relations between labels
- n-way classification, complex tree relation between labels
- multi-class classification (either as ranking output, or set output)
- sequence classification (eg np chunking)
- sentence compression -- deleting selected words
- alignment
- complex structure outputs -- eg parse trees, feature structures, dependency parsing
For these tasks..
- how do we want to evaluate? what's a good loss function?
Challenges:
- we can't just eliminate the wrong answer
- structure over labels
- non-trivial loss functions
- complex input/output relation
- non-trivial output values
- interactions between different sub-decisions
- wide range of features
conventional approach: treat it as a labelling problem. I.e., we're mapping an input sequence 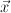 to an output sequence
to an output sequence 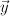 , where we might have a many-to-one relation between x's and y's. (This isn't general enough for all the problems we want to do, but it's a start.)
, where we might have a many-to-one relation between x's and y's. (This isn't general enough for all the problems we want to do, but it's a start.)
Outline of a Solution
We need:
- a quantitative evaluation of predictions. I.e., a loss function. This will be application dependent.
- a class of models. I.e., a set of labeling functions. This generalizes linear classification.
- A learning algorithm. We'll look at extending both the perceptron and the passive-aggressive algorithms.
Loss functions
Examples: hamming distance, Levenshtein Distance, etc. 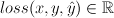
Model
For multiclass classification: we have k prototypes 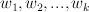 , corresponding to the k labels. For each class
, corresponding to the k labels. For each class  , compute
, compute 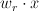 , and take the one that gives the highest score. This is basically dividing the space into hyper-cones (really more like hyper-pyramids), rather than separating it with a single hyperplane.
, and take the one that gives the highest score. This is basically dividing the space into hyper-cones (really more like hyper-pyramids), rather than separating it with a single hyperplane.
Another alternatie: define a feature vector over the entire input/output pair.
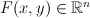
This is fairly powerful -- we're not restricting anything to be local, over the input vector or the output vector. Then, to label, compute:
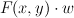
For prediction:
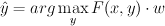
Doing a naive search is expensive, since we have an exponential number of possible output values. So if we have no restrictions on 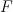 , then doing inference can be intractable. So we restrict the form of .
, then doing inference can be intractable. So we restrict the form of .
Inference: project each F(x,y) onto the weight vector w, and choose the y that is gives the max projection length.
A good 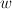 gets things in the right order, and maintains large margins between the best answer and the next-best answers.
gets things in the right order, and maintains large margins between the best answer and the next-best answers.
Using linear models. These are modular, in the sense that:
- we have a factored scoring function
- we can swap in different loss functions
- we can use kernels over the features
Example: multiclass multilabel perceptron
input: `$x in textbb{R}^n
output: `$hat{y} = (w_1cdot x, ..., w_k cdot x)
feedback:
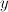 is a set of labels
is a set of labelsloss:
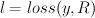 -- where R is the ranking of the labels in the output.
-- where R is the ranking of the labels in the output.if
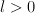 , update weight vectors. I.e., if it gets the example right, don't do anything.
, update weight vectors. I.e., if it gets the example right, don't do anything.Note: the output and the feedback are not the same space!
Update:
find the error-set: the set of
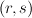 pairs where
pairs where 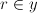 and
and 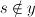 and `$w_rcdot x le w_scdot x`$
and `$w_rcdot x le w_scdot x`$define a matrix
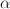 whose rows are correct labels and columns are incorrect labels such that:
whose rows are correct labels and columns are incorrect labels such that: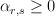
- if
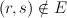 then
then 
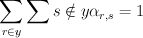
Define an update rate
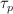 for each label where:
for each label where:- if
 :
: 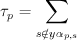
- if
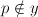 :
: 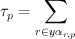
- if
the matrix
may be underspecified by the constraints; in this case, we can pick anything --
it will affect how we move through the space towards the right answer. doing uniform update seems to
work better than doing max update. but max update is faster.
Example: passive-agressive for multiclass multilabel
Basically, we just want to add a margin to what we did with the perceptron version.
So rather than doing no update in the case where we got it right, we'll do no update only if there's a big enough margin between the right one and the wrong ones.
But we know that some mistakes are worse than others -- the loss function is not constant. So use the loss function as our margin.
again, if it's non-separable, we can add slack variables. Also, for certain types of features, it's unlikely that it will be non-separable. finally, we could decide to drop some constraints if necessary.
another advantage of dropping constraints: for complex outputs, we may have an exponential number of constraints. by dropping some, we can find something that works for the remaining ones... e.g., for each new input, run our model and see what we predict, and then take the constraints that say that the correct answer is better than our predicted answer.
see also: "loss augmented prediction"