| Webpage: | http://www.ling.ohio-state.edu/acl08/ |
|---|---|
| Location: | Columbus, Ohio |
45th Annual Meeting of the Association for Computational Linguistics
note to self: search for [XX]
Facial Expressions in human-human and human-machine interactions
Marc Swerts
Different expressive styles reflect emotional state:
- auditory cues (intonation, volume, tempo, etc)
- visual cues
non-verbal features are very important to communication (hard to say just how important).
Facial expressions can "qualify" the information that is being exchanged.
Facial cues can give us info about whether the exchanged information is important, certain, and correct.
Information Importance
- We can mark important info w/ word order, morphemes, lexical items, pitch, prosidy, etc., depending on the language.
- We can also mark it with eyebrow movement
- Visual and auditory cues tend to be synchronized -- it's hard to desynchronize them, even if you consciously try to.
- If you sit on your hands (to prevent gesturing), then your speech becomes more monotone.
How important are visual cues?
- Try combining seperate visual & auditory channels, varying the placing of auditory accent and visual correlates of accent. Ask subjects to decide which word is the "most important."
- Most subjects pay more attention to auditory information
- If they don't pay attention to auditory, then they pay attention to visual
- Reaction time is much slower when the two channels are not synchronized (i.e., visual cue on one word, auditory cue on a different word)
What visual cues are used?
- eyebrow movements
- mouth
- observers may be more sensitive to variation on the left side of the face (from the speaker perspective)
- Experiment: use monotone audio cues, non-monotone visual cues, and black out different parts of the face. See which parts of the face have the strongest effect.
- Top half of face is more informative
- left half of face is more informative (even if you mirror the face)
Information Uncertainty
- speakers communicate information about the certainty of the information they're communicating w/ visual cues and auditory cues.
- e.g.: high intonnation, filled pauses, delays, number of words
- e.g.: eyebrow, smile, diverted gaze, "funny face"
- observers can accurately predict how much uncertainty the speaker feels (ask the speaker to quantify their uncertainty, and then see if this can be reconstructed by observers). This is true if they get just visual cues, just audio cues, or both (more so with both)
- Try the same thing with children: children are less skilled in displaying their confidence level.
- Japanese speakers use a different set of cues. (So uncertainty cues are not (all) language-independent.)
Information Correctness
Visual & auditory cues used to indicate that communication errors are being corrected.
PDT 2.0 Requirements on a Query Language
Jiří Mírovský
PDT = Prague Dependency Treebank
- manually annotated czech text, with 3 layers of annotation: morphology, part of speech & dependencies ("analytical"), "tectogrammatical".
Look at a variety of linguistic phenomena that are annotated in the PDT. What can we learn from these phenomena about what features we need in a query language?
Phenomena
(I found this part of the talk hard to follow -- I think I'll have to take a closer look at the paper if I want to understand it.)
- valency: restrictions on the type of child nodes,
- coordination: we need to be able to skip over conjunction nodes. e.g., "A and B eat and run" -- we need to be able to get at the relation between "A" and "eat", etc.
- predicative complement. the corpus uses a "reference" dependency for this. In this case, we essentially need a variable on an attribute, so we can say that it is the same for two nodes in our query.
- focus proper
- rhematizers
- projectivity, non-projectivity
Query Language Features
Based on these phenomena, the query language should support the following features:
- specify that a node's properties have a given set of values. values specified as:
- constants
- disjunctions
- variables that can match other node properties elsewhere in the query
- constants with wildcards
- numeric constraints (eg x>=5)
- negations
- vertical relations (dependencies between nodes)
- immediate & transitive
- negation
- vertical distance
- number of child nodes
- horizontal relations (sibling node dependencies)
- precedence
- immediate precedence
- horizontal distance
- secondary edges (eg coref) and long-distance relations
- other
- disjunctions over queries
- access multiple layers of the annotation concurrently
- access to the linear text
- skipping nodes of a given type
- skipping sequences of nodes
netgraph: http://quest.ms.mff.cuni.cz/netgraph
Phrase Table Training for Precision and Recall: What Makes a Good Phrase and a Good Phrase Pair?
Yonggang Deng, Jia Xu and Yuqing Gao
- Phrase has become the standard unity in many MT systems.
- In this context, a phrase is just an n-gram, not a linguistic constituent
- Learning phrase translation is important to performance
Given a parallel corpus, we can build a matrix of aligned phrases, and use them to build a phrase translation table. This works fairly well in practice. But it relies heavily on high-quality word alignments.
One solution: better word alignment. But that's hard.
We can treat the process of finding word alignments like an IR task, with precision and recall.
try to answer a few questions:
- how strong is the connection between aligned phrases?
- look at how many crossing boundaries are necessary to translate the phrase
- how confident is the model that it can find a good translation of a given phrase?
- is it worthwhile to find a phrase's translation?
MAXSIM: A Maximum Similarity Metric for Machine Translation Evaluation
Yee Seng Chan and Hwee Tou Ng
Automatic metrics to evaluate MT performance are very useful, but hard. BLUE is the current standard, but some more recent metrics get higher correlation with human judgments.
MAXSIM: a new evaluation metric that gets good correlation with human judgments.
The basic idea is that we map the generated sentence and the reference sentence into sets of nodes, corresponding to some pieces of information (eg ngrams, dependency relations). Then you define functions that decide how similar two nodes are; and construct a bipartite graph with the generated sentence on one side and the reference sentence on the other side; and find the highest scoring fully connected subgraph.. sorta.
Hm, maybe this isn't right. Hmm..
It looks more like they first count shared n-grams counting lexical item and pos; then just using lexical item; and then they do a bipartite grpah match thing.
The Tradeoffs Between Open and Traditional Relation Extraction
Michele Banko and Oren Etzioni
"Open IE": don't pre-specify the set of relations we're looking for; instead, take the relations from the corpus. Use the web. For now, focus on binary relations. Discover relations on the fly -- the model can't be lexicalized in general.
Do IE as a sequence labeleing task, using CRFs. First, use a shallow parser to find entities. Then label the sequence elements as B-REL, I-REL, O, ENT (entity).
Use trusted parses to auto-label some seed training data (treebank). Use rules to extract positive & negative tuples. Features are unlexicalized (though closed-class words are ok), and don't use parse structure -- use pos tags, chunk tags, word shape (regexp type features). No type features for the NEs, but do use a proper/common noun feature.
Relation discovery. There's many ways to express a given relation. Use "Resolver" system, which looks at string similarity and shared attribute features to decide if two strings are referring to the same thing.
This seems similar to doing SRL or semantic parsing, with the addition of a synonymy component that tries to find multiple ways of expressing the same relation.
Regular Tree Grammars as a Formalism for Scope Underspecification
Alexander Koller, Michaela Regneri and Stefan Thater
Showed a plot showing the number of sentences with various numbers of readings.. Many have 1-100, but a significant number are in the thousands-millions range, and there are even a few in the trillions range.
So, we need underspecified scope representations. Use a dominance graph, to show what must scope over what, and then we can resolve this when we need to.
Use regular tree grammars. The semantic representation is itself a grammar. I.e., given a sentence, we map it to a grammar that generates all the possible readings.
We can convert a dominance graph to a regular tree grammar (RTG).
What do we gain by using RTGs?
- We can do redundancy elimination. I.e., given an underspecified representation, with an equivalence relation on the readings, then only keep one meaning from each equivalence class. (In practice, we can't bring it down to one meaning per equivalence class, but we can reduce it a lot.) And we want to do this on the underspecified representation, i.e., without expanding it to the actual readings. (Take advantage of the fact that RTGs can be composed.)
Classification of Semantic Relationships between Nominals Using Pattern Clusters
Dmitry Davidov and Ari Rappoport
Nominals can be related to one another in a wide variety of ways. e.g., time_at, part_whole, etc. What features are useful for classifying semantic relationships between nominals?
Learn "pattern clusters"
- choose some random "hook" words (eg spoon, joking, green) which have high frequencies
- extract all contexts where they occur
- find related target words
- build a group of pattern types (a pattern cluster)
- merge similar groups
e.g.:
- hook word: "spoon"
- target word: "silver"
- patterns: "x is made of y", "x is made out of y", etc
- then look for other pattern clusters that are similar
Vector-based Models of Semantic Composition
Jeff Mitchell and Mirella Lapata
Encode semantics using a vector; and compose semantics of constituents using vector operations.
Semantic space models
- Represent the meaning of a word or phrase or sentence using a word in a vector space.
- usually, semantic vector for a verb reflects the words it co-occurs with.
- how can we generalize this beyond single words, to the semantics of a phrase or sentence?
The simplest idea is to just add or average the vectors of the words; but that gives us a syntax insensitive result. we want to capture the differences in syntax -- in composition order.
Another idea is tensor products, but that makes your dimensionality explode. we could try projecting those down onto a lower dimensional space, but that doesn't work well either.
General model:
p = f(u, v, R, K)
- u,v = semantic vectors for composed vectors
- p = semantic vector of composed phrase
- R = syntactic relationship between u and v
- K = background knowledge
But for now, we'll leave K off, and hold R fixed. Also, assume that p, u, and v are all in the same space.
We could add the vectors, multiply them, or do both (polynomial in the two models)
multiplication is semantically plausible -- it picks out components that are relevant to the two words. E.g., with "horse" and "run", we'll end up with a vector that has dimensions corresponding to underlying words/contexts that are relevant to both horses and running (eg race)
Relationship between this and a probabilistic model -- multiplication -> multiplying probabilities of similarity/co-occurrence..
Improving Parsing and PP Attachment Performance with Sense Information
Eneko Agirre, Timothy Baldwin and David Martinez
WSD helps for pp attachment -- does it help for parsing?
Start off with two lexicalized parsers (charniak and bikel)
Try replacing words with synsets. result: significant improvements in accuracy.
Three issues to consider:
- what level of granularity for word senses? and for what words?
- try both full synsets and semantic files (SF). semantic files are very coarse grained (eg ARTIFACT)
- try both replacing with the synset (generalizing), or concatenating with the synset (specializing)
- try it for nouns and verbs
- how do we do WSD for word tokens?
- see how we can do with gold standard
- try the most frequent sense (either from wordnet directly, or automatically learned)
- morphology (all forms, normalize, etc)
A Logical Basis for the D Combinator and Normal Form in CCG
Frederick Hoyt and Jason Baldridge
CCG is in a sense between dependency grammars & constituent grammars.
Look at some cases where CCG has trouble, and look at adding new rules to help it handle them.
Also look at the general problem of doing this (adding new CCG rules)
CG has associativity -> (AB)C ~ A(BC)
To do wide-coverage CCG parsing, we need to learn the grammar..
D combinator propose as a way to deal with spurious ambiguity.
He went through the rest of this really fast, and I wasn't really able to follow it.
A Generic Sentence Trimmer with CRFs
Tadashi Nomoto
did sentence compression in japanese.
Sentence Simplification for Semantic Role Labeling
David Vickrey and Daphne Koller
path features are often used for SRL; but these features are fairly sparse. how can we simplify the parse tree to give more useful path features for SRL?
The path feature can become quite complicated for even simple sentences, e.g., from adjunction, negation (introduces an extra VP level), etc
>1k commonly occuring paths -- but for a given verb, a random subset of them occur
so.. simplify the path feature. of course we're losing info, although we can do it by just adding a new feature.
- one alternative: use linguistic knowledge to build a hand-crafted system
- another alternative: use a machine learning system
so.. do both.
- first, use hand-written rules to generate a set of possible simplicitations
- then, run srl on each of the simplifications
- then use a classifier to pick the best srl & simplification
- we don't have data labeled with both best srl & simplification, so treat the simplification as a hidden variable
we don't want our simplifications to throw away arguments
try this experiment: for a given arg label, find all the path features (in gold standard training corpus), and look at them by hand. :) [XX]
Automatic Syllabification with Structured SVMs for Letter-to-Phoneme Conversion
Susan Bartlett, Grzegorz Kondrak and Colin Cherry
syllabification:
- input: word in orthographic form
- output: same word with syllable breaks
Deciding on the number of syllables is easy for humans to do; but deciding exactly where the syllable breaks go is a bit harder. What we're really doing here is basically "replicating the divisions in dictionary words," since the input string is an orthographic form, not a string of phones.
Why is syllabification useful? they help humans pronounce unfamiliar words, so they may help machines get correct pronunciation as well.
Example: "mother" -> "moth*er" vs "chemotheropy" -> "chem*o*ther*a*py"
model:
- svm-hmm. seperate the correct structrure y for an input from alternatives by as large a margin as possible
- feature vectors are constructed from complete (x,y) pairs
Tagging scheme: [XX]
- start with N=nonboundary, B=boundary.
- change to N1, N2, N3 -- indicates how long it's been since a syllable break.
- try using a tag set that has onset, nucleus, coda: O, N, C, OB, NB, CB
Features:
- letters in a context window
- n-grams in a context window
Results: it helps (both syllabificiation and speech generation)
A New String-to-Dependency Machine Translation Algorithm with a Target Dependency Language Model
Libin Shen, Jinxi Xu and Ralph Weischedel
different types of dependency link -- eg:
- dependency treebank
- extracted from PTB (eg with magerman's rules)
- inferred from the topology of a derived ltag tree
- learned from unsupervised learning
from source text, generate an ordered dependency tree, and then use that to generate the translated text.
advantages:
- long-distance relations are local in dependency trees
- grounded in lexical items
- can use linguistic information
lessons from prior work:
- syntactic info doesn't help (so far) in reranking
- but it can help in decoding (eg isi system)
For generation, the P(T) is decomposed as the PCFG probabilities of the dependency tree (i.e., product of P(word|parent)).
system components
- rule extractor
- input: bi-lingual training data (aligned)
- output: string to dependency transfer rules. Basically these map lexical items (or spans of lexical items) to dependency treelets.
- decoder
- chart parsing algorithm that produces a shared forest of target dependency trees
need for non-constituent rules -- sometimes the target for a phrase is not a complete constituent -- e.g., something that translates into "trade and economic", but that's not a constituent. This is especially an issue with NPs in cases where flat NPs are used.
solution: "well-formed" dependency structures. Sort of similar to CCG..
Three types:
- siblings with common parent (leave (will) (for boston)
- left siblings ("John will...")
- right siblings ("...for Boston with Mike")
operations: left adjoin, left concatenate. (see paper)
Does it help? baseline: string-to-string MT system (Hiero). Improves performance.
Forest Reranking: Discriminative Parsing with Non-Local Features
Liang Huang
motivation:
- use non-local features for parsing.
- linguistically motivated features for n-best reranking
- n-best list is a bad idea -- too few variations (limited scope) since there's an exponential number of parses; and too much redundancy.
- so how can we incorperate those features back into a chart parser?
so apply reranking directly to the packed forest?
packed forest is basically a generalization of a "lattice" in the finite state world -- instead of a compact representation of lots of paths, it's a compact representation of lots of trees.
it's easy to add local features when doing parse forests. but what about non-local features?
in the exact case, reranking non-local features is intractible. so do an approximation:
at intermediate nodes, do reranking at internal nodes
- use perceptron.. at each iteration:
- get the predicted parse
- if it's not the oracle parse, then update the weight vector
- features are functions from trees to numbers
- first feature is the probability of the tree
- remaining features look at other features of the tree
example of a local feature: when we conjoin two phrases, they should have similar word length
example of a nonlocal feature: when we conjoin two phrases, they should have similar trees
during decoding, do bottom-up, keeping the top k trees at each node. at a given node, we can only find scores based on the features that are available so far, and as we go up, more features become available..
Event Matching Using the Transitive Closure of Dependency Relations
Daniel M. Bikel and Vittorio Castelli
query examples:
- list facts about [event]
- how did [country] react to [event]
we want to know how likely it is that a given sentence contains (discusses) a given event.
low-level features:
- bag of words -- compute word overlap.
- detect named entities -- see if the sentence contains some, all, none of the named entities of a given type from the query event.
high-level features:
- dependency relations
- start with the dependency tree (for both sentence and event query), take the transitive closure, drop edges that have stop words.
- check how many dependencies match
- for dependencies that don't mach, see how many match if we allow for synonym matching.
eg match((Kad, resigns), (Kad, resignation)) = true.
from the dependencies that do match, extract features. E.g., based on the pos of the words, the depth, etc.
why use transitive closure of dependency?
- includes representative power of dependency relations
- remains somehwat agnostic with respect to similarity metrics/formalisms
Simple Semi-supervised Dependency Parsing
Terry Koo, Xavier Carreras and Michael Collins
- statistical parsers make heavy use of lexicalized statistics
- lexicalized statistics are sparse
- idea: use lots of unlabeled data to form word clusters, and then use those in addition to lexical information.
- this requires the use of discriminative parsers
- use a first-order models (pairs of connected dependents) and second-order models (triples of connected dependents)
- use brown algorithm to cluster words -- words merged according tot heir contextual similarity. gives a hierarchical clustering of words, so we can decide what level of granularity to use.
- some of these clusters are similar to parts of speech
- others are more semantic (eg types of market)
- define features based on various granularity levels, pos tags, and lexical items
- do some feature pruning based on counts (800 most frequent lexical items)
Optimal k-arization of Synchronous Tree-Adjoining Grammar
Rebecca Nesson, Giorgio Satta and Stuart M. Shieber
- TAG:
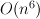 parsing
parsing - STAG: attractive for MT, but NP-hard to parse. :-/
Why is stag hard to parse?
- difficulty depends on the number of independent indices that need to be maintained at a given point in the parse
- this depends on the number of intertwined correspondences
- in the worst case, on the rank,
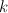 = the number of boxed links in a paired tree.
= the number of boxed links in a paired tree.
shows how to transform an STAG grammar to reduce the rank (where possible)
Enhancing Performance of Lexicalised Grammars
Rebecca Dridan, Valia Kordoni and Jeremy Nicholson
goal of parsing: semantic interpretation.
in most cfgs, the syntax tree doesn't really tell you the argument relation. e.g., "he promised mary to come" vs "he persuaded mary to come" -> agent for "come"
Learning Semantic Links from a Corpus of Parallel Temporal and Causal Relations
Steven Bethard and James H. Martin
want to extract temporal & causal structures from text.
relations:
- cause
- before
- theme
- overlaps
created corpus of temporal & causal relations.
- looked at conjoined verbal events
- frequently expresses both temporal and causal relation
- part of wsj treebank
- events identified automatically
- tagged temporal relations: before/after/no-rel
- causal: causal/no-cause
- 1k event pairs (mostly before)
train models to automatically classify temporal/causal relations
features:
- syntactic: words, lemmas, pos, path, verb features. (paths not that helpful for conjoined events.)
- wordnet: roots, shared roots, least common ancestor, etc
- google features
- direction of causality?
- baseline with most frequent thing for a given TMP relation?
Evolving New Lexical Association Measures Using Genetic Programming
Jan Šnajder, Bojana Dalbelo Bašič, Saša Petrovič and Ivan Sikirič
collocations -- two or more words corresponding to a conventional way of saying somehthing.
use association members to see how closely associated words are, and use them to find collocations
use genetic programming to find association members that are good for finding collocations
encode an association member with a tree structure:
- leaves are constants, n-gram frequencies, n-gram part of speech
- inner nodes: arithmetic operators (+, -, log) and conditional operator: "ith-word of the ngram has POS tag T"
- crossover: randomly choose subtrees
- mutation: randomly remove or insert nodes
- fitness: F1 score on a manual sample with 100 positive examples and 100 negative examples
- parsimony: penalize larger trees
- termination: no improvement on fitness on a validation sample for a few iterations
- goal: evolve an association member that can be used to find good 3-gram collocations.
- initial population: a bunch of random solutions, plus a couple manual ones
- 800 runs with different parameter values
Semantic Types of Some Generic Relation Arguments: Detection and Evaluation
Sophia Katrenko and Pieter Adriaans
generic relations:
- part-whole, cause-effect, instrument-agent, product-producer, origin-entity, content-container
For some sentences, these relations are much easier to find than for others.
Try to learn generalizations about arguments (eg subject must be animate?)
- content-container: constrains the container strongly, the content weakly
Mapping between Compositional Semantic Reps & Lexical Semantic Resources: Towards Accurate Deep Semantic Parsing
Sergio Roa, Valia Kordoni and Yi Zhang
[XX] I should read this paper.
Active Learning with Confidence
Mark Dredze and Koby Crammer
[XX] read this paper
splitSVM: Fast, Space-Efficient, non-Heuristic, Polynomial Kernel Computation for NLP Applications
Yoav Goldberg and Michael Elhadad
SVMs can do nonlinear classification when we us a kernel.
using the dth order polynomial kernel -- considers all d-tuples.
but kernel SVMs are slow at runtime -- run time grows linearly with the size of the training data.
SVMsplit: fast svm with (low-degree) polynomial kernels
why is svm slow? we need to sum over the support vectors, and we need to use the kernel function to combine each support vector with the input value.
split features into two classes: rare features and common features. use different techniques to find the contributions of these features, and combine the result. (inverted index for rare features, and expand the svm kernel polynomial for common features)
Pivot Approach for Extracting Paraphrase Patterns from Bilingual Corpora
Shiqi Zhao, Haifeng Wang, Ting Liu and Sheng Li
Unsupervised Learning of Narrative Event Chains
Nathanael Chambers and Dan Jurafsky
Supporting Searchers in Searching
Susan Dumais
There's only so much you can do with a 2.1 word query.
The interface for search hasn't changed much for a long time.
Use context to support search
- information about the user
- document context -- documents are interrelated
- task context -- understand what problem they're trying to solve
SIS -- stuff I've seen, an internally developed desktop search tool
- 25% of searches contained names
- search for people in roles
- search by time
- halflives: 11 days for web, 36 days for email, 55 days for files
- sort by date is common. accessing by episodic memory is useful.
- highest rank item is not often what we want -- e.g., "highest ranked email from James"
- metadata quality varies a lot -- more for email, little for web, some for files (but it's often wrong)
- memory depends on abstractions. what date to sort by -- access, modified, changed? well, it can depend on the source -- e.g., for pictures when you take them (not upload them), for calendar items the date of the item, for web when it's seen, etc.
- incrementally refining queries