Coreference Resolution in a Modular, Entity-Centered Model
Separate out different sources of information for coref:
- Discourse cues -- more "closed-class"
- Semantic cues -- more "open-class"
In prior work, semantic cues haven't been used as much (as successfully), partially because they're hard to learn (sparse).
In this work: use unsupervised learning to create a semantic model
Types of coref system:
- Antecedent-based: link a single mention to a single antecedent phrase (eg pronouns)
- Entity-based: maintain a set of salient entities, and link each mention to an entity.
In this work:
- Use entity-based resolution to model semantic facts
- Use antecedent-based model to model discourse facts
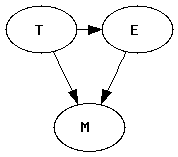
To model entities, we create an "entity type".. Each entity belongs to a type.
Model Outline
- Semantic component:
- Start with a set of types
 , and use them to generate a set of entities E.
, and use them to generate a set of entities E. 
- Start with a set of types
- Discourse component:
- Input = syntax tree X
- Output is a set of assignments of indices to NPs.
- Mention component:
- Generates mentions M from E and Z
Semantic Module
- Learn 16 entity types. E.g., person. Each type has:
- Nominal (NN) head distribution: When it's a nominal, what heads does it have?
- Proper (NNP) head distribution. Distribution over possible heads (for people: last names)
- NSUBJ Gov head: What verbs does this entity type act as the subject for?
Entity = {T,L}:
- T = type
- L = {Proper Head(s), Nominal Head(s), Noun Modifier(s)}
E.g, L={[Obama], [president,leader], [Mr.,]}
Generative model:
- Choose a type
- Generate L
- For each component of L (eg nominal heads):
- Generate distribution of length of the list
- Generate individual items in the list
Discourse Module
- Input: tree T
- Latent intermediate variable: A
- Mention assignment
Basically each mention can either take a new entity assignment, or be co-referent with one of the entity assignments we've already chosen.
Use log-linear "antecedent affinity" functions to decide what we want to be antecedent with
Some syntactic configurations essentially "lock" coref. E.g., appositives force us to make two things co-referent. This can help us build a richer semantic model.
Mention Module
- Mention is a noun phrase
- We can extract property/word pairs from the NP. E.g.: <Proper Noun, Obama>, <NSubj Gov, said>
Some words that are associated with an entity are entity-specific. Others are licensed by the entity type (e.g., people say things).
T=Type; E=entity; M=mention
Training
Use staged training: fix some parameters, and learn others.
Type Creation
Start with some prototypes for each type
e,g,: person -> president, director; vehicle -> car, plane
Then learn the distribution of nominal heads, nsubj gov, etc.