| Location: | San Francisco, CA |
|---|---|
| Date: | January 8-11, 2009 |
| Webpage: | http://www.lsadc.org/info/meet-annual.cfm |
83rd Annual Meeting of the Linguistic Society of America
Tracing Semantic Change with Latent Semantic Analysis
Eyal Sagi, Stefan Kaufman, Brady Clark (Northwestern University)
Words change their meaning over time.
- broadening: a word describes a larger class of entities (eg dog)
- narrowing: a word describes a more specific class of entities (eg deer)
- grammaticalization (eg 'do')
Historical semantics: To identify a semantic change:
- collect examples of the word from a corpus
- identify verious uses of the word or multiword construction
- examine for changes in the patterns of use
Unfortunately, this is expensive. In particular, it requires:
- deep knowledge of corpus
- lots of interpretation
- lots of time
- intuition about what changes are likely
Try to do this more efficiently (or at least to approximate it) with LSA.
Semantic density: the average angle between vectors in the semantic space generated by LSA. If a group of words are similar in meaning, then they have a high semantic density. (I'm assuming that "average" here means mean angle.)
Look at the semantic density of the contexts where a word appears. So if the use patterns of a word broaden over time, then we expect the semantic density to decrease (i.e., the avg angle to increase); and if the use patterns narrow, then we expect the semantic density to increase.
Tested on Helsinki corpus. One issue: spelling changes make things difficult.
(software used for LSA: infomap)
First example: 'do', which was originally used for specific meanings, but became semantically blanched (so it appears in more general contexts).
Q: intuitively, if your graph has two peaks, that probably reflects the fact that there are 2 different ways that the word gets used (call them A and B), and the lower peak shows both A-vs-A and B-vs-B, while the higher peak shows A-vs-B and B-vs-A. So perhaps there's a better way to do visualization of this data, e.g., based on clustering.
Q: To what extent do these changes reflect changes in genre in your corpus, rather than changes in word meaning.
The Fox is Afraid: Evidence for Items and Generalizations
Adele Goldberg, Jeremy K. Boyd (Princeton University)
Looking at the class of adjectives like "afraid" that start with "a-" (schwa) and are 2 syllable, unstressed-stressed.
E.g.: asleep, afloat, alive, abashed, ablaze, afraid
Properties of adjectives:
- modify nouns
- can be modified for degree
- appear predicatively and attributively
A-adjectives are atypical, in that they are very rarely used attributively:
- ?? the asleep child
- ?? the alive monster
- ?? the afraid rabbit
To test this claim, use google to search for attributive and predicative uses of a-adjectives. Google confirms that a-adjectives resist attributive usage.
One possibility: it's the semantics. In particular, whether the adj describes a stable vs unstable property. a-adjectives are usually unstable. But if we try using similar words (e.g. floating vs afloat), then the attributive/predicative is much more balanced.
Another possibility: it's the 2 syllable unstressed-stressed pattern. But this doesn't hold up to the data.
Another possibility: historical persistence. Most of these words derivationally come from PPs. E.g., "on sleep" → "asleep" and "on float" → "afloat" and "in bloom" → "abloom". You don't use PPs attributatively, so maybe this is getting preserved.
So the idea would be that the learners record statistics about a word's usage patterns, and preserve those over time, despite language change.
Some adjectives that don't mind attributive: absurd, astute, adult. But these are really in a different category: e.g., "a+bsurd," we don't have a word "bsurd" and "a+dult" vs "adult". But c.f. "asleep" → "a+sleep" etc. So we may refine the category to be:
- starts w/ a (schwa)
- 2 syllables, unstressed then stressed
- decomposable where 2nd syllable has a recognizable meaning
Question: do these 3 properties really describe a category that is psychologically real? In particular, do we generalize the prohibition against attributive usage to words that have these 3 properties, even if they're not historically derived from PPs.
Try an experiment that uses novel words, to see whether they use them attributively or predicatively. We find that for real a-adjectives, probability(attributive) is much lower than it is for non-a-adjectives. For novel (made-up) a-adjectives, probability(attributive) is still lower, but the difference is much smaller.
Second experiment: first, expose subjects to a-adjectives, used in relative clause position only. Then see how they use them in experimental condition. This makes the probability(attributive) for novels much closer to what it was for real a-adjectives.
Slides available at: http://www.princeton.edu/~jkboyd
Grammaticalization and Lexicalization in Hindi Light Verbs: Using Corpus Data Towards an Integrated Model
Shakthi Poornima, Robert Painter (SUNY Buffalo)
Constructions w/ high frequency become grammaticalized.
Determine the degree to which Hindi light verbs are involved in grammaticalization and lexicalization
Hindi light verbs:
- inflect for number and gender
- can assign case to the subject
- can be combined w/ another verb (but don't need to be)
- semantically, add aspectual meaning. also semantically can add some subtle semantic notions (e.g., surprise at the semantic content of the sentence, suddenness, regret, violence, etc)
- fuse with the main verb
- mark perfectivity
- have undergone some semantic bleaching
- are a closed class (about 12)
Cross-linguistically, light verbs do not pattern the same as auxilliaries. In particular, Hindi has aux verbs, and the two classes differ in various syntactic properties. (E.g., light verb must always preceed the aux verb -- aux verbs come last).
Diachronic issues: many dialects, contact between Dravidian and Hindi.
Claims:
- some hindi verbs have diverged historically to form both auxilliary and light verbs
- within light verbs, there is grammaticalization to varying degrees
- some light verb+main verb combinations are becoming lexicalized
Metholdology:
- picked 12 verbs
- sampled 100 sentences
- hand coded whether each verb was light
Results:
- some verbs can be used as MV (main verb), LV (light verb), and AUX (auxiliary). e.g., go and fall. - aux usage is more common than MV or LV usage. - account: verbs have diverged
- Syntactic MV-LV combinations
- give, take. Get new meaning (e.g., benefaction -- give=benefaction for someone else, take=benefaction for self))
- Lexical MV-LV combinations - idiomatic semantics
- Light verb "put" onl selects for verbs of creation or destruction. (break completely)
(There were several more specific examples)
Claim: grammaticalization and lexicalization are two endpoints of a gradient:
<--------------------------------> L3 L2 L1 G1 G2 G3 (lexialization) (grammaticalization)
I may not be understanding the proposed model entirely, but from what I do understand of it I don't find it very compelling/motivated.
ORIGIN and Its Connotations: A Cline of Semantic Degrammaticalization
Stefanie Kuzmack (U. Chicago)
It's generally accepted that there's a strong tendency in language for constructions to grammaticalize, and unusual for constructions to degrammaticalize.
One way that degrammaticalization can happen is euphamism. But this may be more of lexicalization rather than degrammaticalization.
But here we see a cline of degrammaticalization, eg:
- ORIGIN > LEXICAL CONNOTATIONS OF ORIGIN
Where origin refers to where someone comes from.
Example: outlandish. Originally, this meant "from the outlands," but came to mean strange...
Two subclines:
- ORIGIN > COMPARITIVE: 'from X' > 'like X' (ish, esque, -(i)an)
- ORIGIN > LANGUAGE: 'from X' > 'the language of X' (ish, ese)
Derivational affixes are sometimes claimed to be less grammatical than inflectional affixes, so a change from inflectional to derivational is an instance of degrammaticalization. (eg Lehmann). But Haspelmath argued the converse. So.. judge each affix on a case-by-case basis.
Example of a very lexical affix: -ism.
But the affixes discussed here start out as being very grammatical.
ORIGIN → COMPARITIVE
-ish
In 1200s, used primarily for national names: English, scottish, Spanish.
Then generalized to be "characteristic of X"
In 1300s, used to mean from/of without nationality. E.g.: foolish, devilish
qualifier -ish eventually underwent morphological degrammaticalization, so it can now be used as an independent word:
A: Can you swim well?
B: ish.
Around 7ish
From what I've heard, ish.
-esque
Derives from the same morpheme as -ish, but borrowed various times
In present english, usually used w/ comparitive sense: picturesque, statuesque, Kafkaesque
Lexical meaning: not just like X, but in the style of X. Compare Kafkaish and Kafkaesque.
Several companies have been named "Esque" after this affix, to capture the notion of "style of." (This is lexicalization, not degrammaticalization, but shows that the 'style' meaning is highly salient)
-(i)an
Usually origin, but sometimes comparitive of characteristic. E.g.: Dickensian, Beethovian. This suffix hasn't progressed to be used w/ non-origin words (like "foolish" and "picturesque")
ORIGIN → LANGUAGE
-ese
Portguese, Maltese, etc. Originally refered to the origin of something, but changed to refer to the language of the place. E.g., Milanese was used as early as 1484, but was only used to refer to the language starting around 1642.
Late 1800s, started to use with non-locational stems. Stagese, newspaperese, journalese.
-ish
Bostonish, Californish, Washingtonish. These all have place stems, but they indicate language, not the place:
- 'wata' is Bostonish for 'water'
- Speak Californish
Q from audience: how do we distinguish between lexical & grammatical? One argument: origin is semantically close to genitive, and genitive is thought of as grammatical. There's definitely differences in opinion -- e.g., is the preposition "from" grammatical or lexical?
Arabic Causative/Inchoative Verb Alternations in their Genetic and Geographic Context
Kevin Schluter (U. Arizona)
Semantics tend to correlate w/ morphology -- in particular, morphology can display whether a word is causative or inchoative.
Typology: look at what is possible in human language, and use that to inform us about a universal theory of grammar. Modern typology seeks to explain tendencies and their rare exceptions.
Why do we see the typological tendency patterns that we do? E.g., why are some word orders more common than others.
Iconicity in derivations. Derivations transform a (more) primitive form to a derived one. There's a basic form and a derived form, and the relation between them is asymmetric. E.g., we can have causative transformations and anticausative transformations.
Inchoatives and causatives differ in terms of agentivity.
- inch: The stick broke
- caus: The girl broke the stick
Doesn't correspond to transitivity. E.g., c.f.:
- Mr. R. taught me history.
- I learned history.
Do determine the direction of a transformation (i.e., which is the more primitive form), we typically look at:
- Phonological markedness
- Direction of neutralization
- Productivity
Marking inchoative vs causative:
- Inchoatives: Prefixed n- or t-; or infixed -t-
- Causative: reduplication, prefixed h-, etc.
Look at 31 pairs of causative/inchoative verbs in 5 languages
- small number of languages reflects the fact that it's hard to find sufficiently informative dictionaries. Dictionaries are somewhat problematic because dictionary authors have their own assumptions, which may or may not be correct.
Data: table with columns for: concept, inchoative, causative, derivation type. E.g.:
| Concept | Inchoative | Causative | Type |
|---|---|---|---|
| Disolve | dab | dawwib | Causative |
| burn | tihraq | hraq | Anticausative |
| etc. |
- Inherited transitivity profile predominant
- Contact effects seen only in long duration (2k+ years) or
- Creolization (cf Gragg 2008)
Implications
- preference for economy in constructions (preserve morphology)
- change requires long time and distance or intense contact
Explaining Alienability Contrasts in Admonical Possession: Economy vs Iconicity
Martin Haspelmath (Max Planck Inst. for Evolutionary Anthropology, Leipzig)
General idea: use shorter encodings for higher frequency items. The overall story seemed plausible, but he glossed over most of the examples, so it was difficult to verify what he claimed.
Q from last talk: When we have 2 morphologically related forms of a word, one is morhpologically primitive and one is morphologically derived. What dictates which form will be morphologically primitive, and which will be derived? Use the more frequent one.
In this talk:
- inalienable possession = construction used with kinship and/or body part terms
- alienable possession: construction not used with kinship and/or body part terms
Universal claim: if a language has an adnominal alieanability split, and one is overtly coded while the other is zero-coded, then the inalienable construction is always the zero-coded form.
E.g., if exactly one of the two possession types (inalienable vs alienable) is marked, then it will be the alienable type that is marked.
Iconicity explanation: inalienable possession is a more "iconic" form of possession, so it doesn't need to be marked.
Economy explanation: the reason for this is that the inalienable form is more frequent.
E.g.: for body-type terms, about 46% of occurrences of these terms are used in a possessive context, so overt possession marking is somewhat redundant. For kinship, it's 49%.
How is the frequency explanation better than the iconic explanation?
- There was an explanation with the middle position of the alienable marker, but I didn't quite follow it.
Cohesion scale (Haiman):
- X word Y -- function-word expression
- X Y -- juxtaposition
- X-Y -- bound expression
- Z --- portmanteau expression
So in addition to overt vs non-overt contrast, we should have eg contrast between bound & juxtaposition, and juxtaposition vs function-word.
- High token freq leads to short coding
- Also leads to bound expression
- Portmanteau expression is predicted to occur if the combined expression has high absolute frequency. (c.f. short and bound expressions, where high relative frequency may be enough.)
Some other predictions...
- Length of the possessive marker is shorter in the inalienable construction.
- Nouns that can't be possessed
- Nouns that must be possessed (possidend nouns)
Where can these contrasts come from diachronically?
- sometimes: differential reduction: e.g., inalienable form goes from juxtaposed to bound, while the alienable form does not.
- more often: differential expansion/inhibition of a new construction. e.g., novel construction forms for the alienable form, but doesn't spread into the inalienable forms. High frequency inhibits spread into inalienable forms.
From Single Word to Verbal Clause: Where Do Simple Clauses Come From?
T. Givon (U. Oregon)
Givon made the argument that it's reasonable to expect some parallels between the mechanisms used for language learning, language evolution, and language change over time. That overall argument seems reasonable enough to me, but the specifics of his arguments seemed a little odd to me.
He started out by basically saying that complexity is hierarchical structure. There are some issues with that, but we'll put them aside for now. Then he argues that just saying that there's a generic MERGE operation that puts things together isn't really explanatory -- we need to know what can we put together, and why can they go together, and how do they go together, etc. This is all perfectly reasonable.
His counter-story seems to be something like that we can juxtopose things that are semantically related, without combining them linguistically. In those contexts, he gives some evidence the juxtoposed things need to be directly adjacent. So then he says that language is basically generalizing this, and perhaps allowing things to be combined that are not directly adjacent.
But I found his examples to be not very compelling (including the evidence that juxtoposed things need to be adjacent). The evidence came from Ute narratives, English dialogs, English language learning, and a couple other places.
See the handout for more info & for the examples.
Over-extension patterns in spatial language: The case of containment
Megan Johanson (University of Delaware), Stathis Selimis (National and Kapodistrian University of Athens), Anna Papafragou (University of Delaware)
Relationship between spatial language and cognition?
- When children learn spatial language, they learn it in fairly regular patterns; and they over-extend it in fairly regular patterns.
- e.g., children use "open" for turning on lights, even in languages (such as english) where this isn't licensed.
- These patterns may piont to 'natural' concepts or biases in spatial cognition.
Study 1: acquisition of motion path expressions
Examined in English (which uses mostly PP) and Greek (which uses PP and V)
source/goal asymmetry: goal is privileged over source.
Examine containment. Expressed in PPs (into) and verbs (enter). Containment is one of the 1st spatial relations that's learned.
stimuli:
- figure (soccer ball) and ground (various abstract 3d shapes)
- 8 spatial relations (contain, cover, etc)
- both source and goal versions
- animations -- e.g., the soccer ball goes into (or comes out of) an open cylinder.
- ask the child to describe the motion (what did the ball do?)
Younger group over-extend the use of containment adpositions to "behind" and "under" situations much more than older children do (esp for goal scenes). I.e., if the ball comes out from behind a block, the child will describe it as "the ball came out of the block" rather than "the ball came out from behind the block"
Possible explanations?
- Conceptual or perceptual difficulty? Probably not: previous research shows that children of this age discriminate occlusion from containment
- Just using "out of" for occlusion? No -- for the 'under' relation, the object wasn't occluded.
- So perhaps the child is forming a conceptual class that includes: in, behind, and under.
- Younger group don't use 'under' or 'behind' very often -- so they co-opted "out of" for these cases. But they didn't use "out of" for other spatial relations.
Study 2: cross-linguistic
- 12 speakers, 12 languages (one informant/language)
- similar to 1st experiment, but 4 examplars for each spatial relation
Findings: among languages that use verbs to express containment, the containment verb often gets extended to both the "behind" and the "under" relations. More extension for sources than for goals.
When the Shoe Fits: Cross-Situational Learning in Realistic Learning Environments
Lila Gleitman, Tamara Nicol Medina, Jesse Snedeken, John Trueswell (University of Pennsylvania)
(Formerly titled: Rapid word learning under realistic learning conditions)
Cross-situational learning: find a set of possible meanings in each situation, and intersct the sets across all situations in which a word occurs to determine the meaning for that word
Issues:
- Frame/level of description: dog vs animal vs terrirer vs fido
- Referential uncertainty: which object is referred to?
Xu & Tenenbaum use Bayesian inference to look for "suspicious coincidences"
Yu & Smith: we can learn word-object associations in spite of referential uncertainty. (Using made-up words). But the experiment is very simplified with respect to what babies actually encounter. Natural learning environment is typically very cluttered.
Exception: joint attention between the parent and child, with parent naming the attended object.
Stimuli: large video corpus of parent-child interactions in natural settings.
Background: Norming study
- Identified 48 most frequent words
- Randomly selected 6 instances of each word
- Each instance edited into a 40-second vignette
- sound turned off
- utterance of target word indicated by a BEEP (occurs at 30 second mark)
At the end of each vignette, the subject is asked to identify the word.
Utterances were all independent, so no opportunity for cross-situational learning
Baseline accuracy for identifying a word calculated on a per-vignette basis. E.g., in some vignettes, it was very easy to guess, and for others, much harder.
For 90% of Vignettes, <33% of subjects guessed the word correctly (low-informative) For 7% of Vignettes, >50% of subjects guessed the word correctly (high-informative)
Cross-Situational Learning Study
- Same paradigm, but use a nonsense word rather than a beep, e.g. "VASH"
- Present one instance of each word, then a second instance of each word, etc.
- At the end of all vignettes, the subject is asked the meaning for each word, and to give a confidence rating for that meaning.
Questions: - can subjects learn words from multiple low-informative vignettes? or do they also need some high-informative vignettes?
For 8 target nouns: 1 high informative, 4 low informative For 4 target nouns: 5 low informative vignettes
Four different orders:
- H-L-L-L-L ('first')
- L-L-H-L-L ('middle')
- L-L-L-L-H ('last')
- L-L-L-L-L ('absent') -- n.b. 5th vignette is repeat of 1st vignette
Results:
- For 'absent' case, accuracy doesn't really increase much above 20%, despite repeated exposure.
- For 'first' case, accuracy drops after the H case, but stays around 35%.
- For 'middle' case', accuracy jumps up for H case, but then drops back down to 20% by the last exposure.
- For 'last' case, accuracy increases a little for the H case, but final accuracy is around 20%
What have we learned about learning?
- gradual learning from partially informative instances is small to nonexistent
- learning appears to require high-informative instances
- low informative instances have a corrupting influence on later-occurring high informative events
It looks like learning may take place more through "epiphany" moments, rather than through gradual learning.
If we look at self-reported confidence, then it appears to increase if they first figure it out and then get reinforcement that they might be right.
Implications: word learning is rapid, but not quite incremental. Instead, it requires the occurrence of a highly-informative instance.
Difference between experiment and real world:
- greater delay between instances of a novel word in the real world
- multiple high informative learning instances in the real world
- subjects were forced to give a guess even for low-informative instances. This puts extra weight on these instances. In the real world, they may just ignore these instances.
Young children use both animacy and role to categorize event participants
Ann Bunger, John Trueswell (University of Pennsylvania)
Look at how and when children learn conceptual features that underlie noun arguments. Some of these features appear to be available to children pre-linguistically.
Language maps to conceptual representations..
- Nouns → participants
- Verbs → relationships
Look at how we link syntactic arguments & event participants.
Children can use the syntactic position of a word to understand what role the corresponding participant plays in an event.
Gordon 2004: Nonlinguistic event representation: man, woman, doll, give, hug. When there's a give event, the child attends to all 3 participants, but when there's a hug event, the child attends to 2 participants. I.e., children have a pre-linguistic understanding of what the participants of an event are. Questions: (i) is this an event-specific phenomenon, or can children abstract across different categories of event participants? (ii) which features are driving attention to these particular participants?
Look at 2 properties of participants:
- animacy (animate vs inanimate)
- role (agent vs patient - really causer vs undergoer)
Methods: - videos of causitive events - subjects:
- preschool children (avg 4.25 yr old)
- upenn undergraduates
- B&W video, patient reinforced by color & sparkly animation
- ask subjects to guess which object will change color (pointing)
- data: eye tracking and pointing
4 kinds of event:
- AA: animate agent, animate patient
- AI: animate agent, inanimate patient
- IA: inanimate agent, animate patient
- II: inanimate agent, inanimate patient
16 trials, 2 phases:
- training phases: 8 events. divided into 5 groups: AA group only sees AA events, AI only see AI, etc, and MIXED sees all types.
- test phase: 8 events, incl each event type
What do subjects use to decide?
- Subjects in AA or II group: can use event role
- Subjects in AI or IA group: can use animacy or role
- Subjects in MIXED: can use event role
Results:
- subjects in AA group do well, so clearly the are capable of making use of the event role distinction
- subjects best at picking out animate patients, unless they were in AI group (where they were trained to pick out inanimate patients)
Conclusions: - adults and children use event role to categorize event participants (in non-linguistic contexts) - animacy of event participants may interfere with this categorization
The representation and processing of measure phrases in four-year-olds
Kristen Syrett, Roger Schwarzschild (Rutgers University)
What different interpretations do numbers have in different syntactic contexts?
Children must learn that.. - numbers describe cardinality of sets (2 cherries) - numbers are used with measure words (2 pounds of cherries) - measures can be used as modifiers (2-pound cherries)
Focus on measure phrases (MP), as attributive modifiers
- Syntax: 2-cup card vs 2 cup-cards
- Semantics: 3-pound cherries vs 3 pounds of cherries
- processing of numerals incrementally (garden-pathing): 2-cup card vs 2 cups of cards
Expreiment 1: Syntax
Can children distinguish [[2-cup] card] from [2 [cup-cards]]
2 cues: prosidy (pause, stress) and number marking.
Paradigm: show students both (e.g., a 2-cup card and 2 cup-cards), and ask them to point to the "2-cup card"
3 year olds are more or less at chance, and 4 year olds are much higher. But in both cases, there's a bimodal distribution, and if you split them out, then some clearly make the right one and some don't.
You can query the child to determine what cues they used.
Most children rely on prosodic & number cues.
So, we'll assume the children can get the syntax right.
Experiment 2: Semantics
Do they get the semantics right?
- 3-pound cherries ("attributive") vs 3 pounds of cherries ("pseudopartitive")
Pseudopartitive: - marked by of - number marking on MP (measure phrase) head - measurement of entire quantity - monotonic: if you take some away, the phrase no longer accurately applies
Attributive: - no of - no number marking on MP head - measurement of the individuals - nonmonotonic: if you take some away, the phrase still accurately applies
Method: short vignette plus question. 3 items: n-pound strawberries, 4-foot ribbon, red car (filler)
Vignette: I bought 3-pound/3 pounds of strawberries. Then a mouse ate some. Do I still have 3-pound/3 pounds of strawberries?
Results: children got it right, for the most part. For the attributive strawberry case, children acted near at chance (not statistically significant difference from 50%). For mass case (ribbon), it looks like they understand, for count (strawberries), they may not understand as well.
Experiment 3: Processing
Display with 4 cells: target, competitor, and 2 distractors.
Example: point at the 2-cup card. 4 displays: 2 distractors, a card w/ 2 cups, and a competitor with 2 cups, each containing cards. vs "2 cups of cards".
- Kids were good at picking "2 cups of cards" correctly.
- Kids asked to pick "2-cup cards" were at chance: [[2-cup] cards] vs [2 [cup cards]]
- Kids asked to pick "2-cup card" were below chance (competitor = 2 cups of cards)
Explanation: If the first thing you hear is "2", then you may immediately rule out the single card with 2 cards. I.e., garden pathing.
Focus identification in child Mandarin
Peng Zhou, Stephen Crain (Macquarie University)
Consider a picture with a pig holding a flag and a rabbit holding a flag and a balloon. C.f. the 2 sentences:
- Only the pig is holding a flag.
- The pig is only holding a flag.
Adults mark the first as incorrect and the second as correct.
Children mark both as correct.
One proposal: children are VP-oriented -- they tend to associate the focus operator (only) with the VP regardless of its surface position.
Another proposal: the kids basically ignore "only"
Method: show a vignette, Kermit puppet describes it, ask child if Kermit is right or wrong. 2 test conditions: one where the adult would call it true, one where the adult would call it false.
Results: children reject the sentence 85-90% of the time for both the adult-true and the adult-false case.
Asking kids for explanations, we see that children tend to associate the focus operator with the VP, not with the subject NP, regardless of where it appears in the sentence.
Adult interpretation:
- [IP [QNP [Adv only] [NP john]] [VP ate an apple]]
Child interpretation:
- [IP [Adv only] [IP [NP John] [VP ate an apple]]]
Experiment 2: rather than asking if Kermit got it right, ask questions like "who do you think can do X"? Under this condition, where the subject is more focused, the kids perform much more like the adults do.
Experiment 3: insert a negation, which should block "only" from applying to the VP, because of the intervening NEG (not). Subjects hear Kermit make 2 assertions: one positive, one negative. For the adult-true condition, if the subject hears the negative example first, they act like the adult 87.5% of the time; but if they hear the positive example first, they only act like the adult 12.5% of the time. (It's presumably just an odd coincidence that these two numbers add to 100%.)
The earliest stages in the acquisition of focus expressions
Anna Notley, Stephen Crain (Macquarie University)
(I didn't take notes during this talk.)
Girlz II Women: Age Grading, Language Change, and Stylistic Variation
John Rickford (Stanford University)
From a synchronic pattern, we can't really know how language changes:
| Synchronic pattern | Diachronic | Correlate | Interpretation |
|---|---|---|---|
| Individual | Community | ||
| Flat | Stable | Stable | Stable |
| Regular slope w/ age | Change | Stable | Age Grading |
| Regular slope w/ age | Change | Change | Lifespan Change |
| Regular slope w/ age | Stable | Change | Generational Change |
| Flat | Change | Change | Communal Change -- e.g., lexical introduction |
Foxy & Tinky (at 13 and 15) had their language very strongly marked by patterns characteristic of AAVE (african american vernacular english).
Both reinterviewed at ~35 years old. As adults, they displayed a large reduction in AVEE patterns, towards mainstream language usage patterns. But they're still not standard speakers, and are further from standard than their parents were at a similar age.
If we look at teenagers today, they act like Foxy & Tinky did 20 years ago. So it's not just communal change.
(The remainder of the talk was interesting, but I didn't take notes.)
Symposium: Meaning and Verification: Towards a Psychosemantics for NL Quantification: Introduction
Jeffrey Lidz (University of Maryland)
http://www.languagescience.umd.edu
Looking at traditional semantic questions, and bringing psycholinguistic info to bear on them.
Questions via Chomsky:
- What do we know when we know a language?
- How do we acquire that knowledge?
- How do we put that knowledge to use?
Questions via Marr:
- What functions does the system compute?
- How is that function computed (by what algorithm)?
- How is that algorithm implemented?
Contrast between what is computed, and the algorithm used to compute it. Chomsky refers to this as the E-language/I-language distinction.
C.f. Frege-Church contrast between a function as extension (set of pairs) vs intension (procedure/algorithm that computes output for an input).
Extenstionally, the following functions are the same:
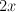 vs.
vs. 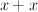
But intensionally, they're different.
If we think of languages as mappings from signals to interpretations, then we can either model that extensionally or intensionally.
How can extensionally equivalent theories differ empirically (if they can at all)? When is a theory theoretically adequate?
Given any one specification of a function, we can come up with others that are equivalent. I.e., given any one E-theory, there will be many corresponding I-theories.
Questions via Chomsky:
- What do we know when we know a language? A specific I-language. Providing an E-language isn't sufficient. Need to provide an algorithm.
- How do we acquire that knowledge? Select a specific I-language.
Traditional worries:
- how much commonality is there between different individuals' I-languages?
- if language is a tool for communication, then maybe E-language is more important than I-language?
- Slippery slope to (bad) verificationism: no principled distinction between how speakers (i) represent a yes/no question, and (ii) come up with an answer to the question. These two need to be kept separate.
"Most" as a case study:
- interesting as a determiner.
- related somehow to representations of numbers.
- experimentalists can exploit independent studies of perception & numerical competence.
- the "logical" vocabular has long seemed like a promising arean for distinguishing (i) "canonical" procedures that specify truth-conditions, and (ii) "evaluation" procedures that can be used to decide whether a given sentence is true.
"Most dots are blue"
C.f. two I-theories that are extensionally equivalent:
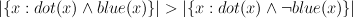
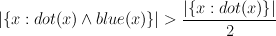
But we don't necessarily need cardinality.. E.g., we can get along with a OneToOne relation instead.
For acquisition, how do kids learn the I-langauge algorithm for most? Do they shift from one kind of algorithm to another? To distinguish this type of thing, we can't just check under what conditions a speaker thinks that 'most dots are blue is true.
In order to evaluate the truth of a sentence, we need to bring in and integrate various cognitive resources. For 'most'...
- parallel individuation
- approximate number system
- precise number system
If we can understand the cognitive systems that the linguistic system interacts with, that can inform us about constrains on the linguistic system, which may help us understand how it (likely) works.
Cognitive science of number
3 important systems:
- parallel individuation. The number of objects that can be simultaneously tracked (while focusing on a focus point) is about 3 (with some variation between individuals). Similarly, if kids are shown two buckets being filled with cookies, they will choose the one with more cookies if
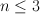 for each bucket (eg 2 vs 3) but will choose at chance if
for each bucket (eg 2 vs 3) but will choose at chance if 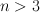 (eg 3 vs 4)
(eg 3 vs 4) - approximate number system. As n gets higher, the subject becomes closer to chance. Discriminability of 2 sets depends much more strongly on their ratio, rather than on the absolute numbers. "Mental magnitude." In babies: habituated to a specific number of dots, then they see a different number. If you double the number of dots, they'll dishabituate. This is ratio dependent. At 6 mos, can do 1-vs-2 but not 2-vs-3, at 10 months, can do 2vs3.
- precise number system. e.g., exactly 212. Kids have precise numerality for 1 at 2.75yrs, for 2 at ~3yrs, for 3 at ~3.2yrs, and for full cardinality at ~3.5yrs.
Beyond truth conditions: The semantics of ‘most’
Jeffrey Lidz, Paul Pietroski, Tim Hunter (University of Maryland), Justin Halberda (Johns Hopkins University)
Interface transparency thesis:
- meanings are more fine-grained than truth conditions
- Distinct formal specifications of meaning are distinct psychological hypotheses (and not notational variants)
- Meanings provide canonical verification procedures
- To distinguisth them: verification procedures are biased to compute the relations directly expressed in the meaning.
Sentences will be things like: "Most of the dots are yellow"
Consider "most of the X's are capitalized with the picture:
X x X x o X x X p P X q
Here, the x and X are in an easy-to-see 1-to-1 relation, so we can know that there are more X's than xs, without counting.
Three theories:
- We use correspondences
- We use the approximate number system
- We use the precise number system
Tree of possibilities:
[most [exact-most [cardinality count 1-to-1 ANS] [correspondence count 1-to-1]] [fuzzy-most [ANS [ANS]]]]
- Level 0 (root) is word "most"
- Level 1 is computational truth conditions
- Level 2 is families of algorithms
- Level 3 (leaves) is further distinctions between verification
Ask subjects to judge (after 200ms) whether most dots are yellow.
- Performance is affected strongly by ration, but is not depend on whether they're paired or put in a column.
- Not enough time: so they're not using the precise number system
- Because pairing and columns don't help: they're not using the correspondence systems
- So the underlying cognitive system is probably the approximate number system
Next questions:
- even if we're representing most with (approx) cardinality, there's many ways to represent it. E.g., more than half, more yellow than non-yellow, using subtraction, etc.
- Why is discrimination so poor for this task (subjects seem to need a ratio of .3 or so)
For the next experiment, they varied the number of different colors that were being distinguished between. This lets us tease apart which algorithms might be used, because different algorithms require different pieces of information, and we will be limited in processing this information as the number of colors increases.
E.g., if we're deciding whether "most of the dots are blue," with 4 colors, do we look at the number of blue vs the sum of the numbers of the other colors? Or do we compare the number of blues to the total number? (note that the visual system doesn't really allow us to attend to "non-blue dots". If the first theory is true, then performance should be good for up to 3 colors, and drop after that. If we're doing 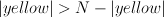 , then the number of colors shouldn't affect performance.
, then the number of colors shouldn't affect performance.
Another option is that we use different mechanisms for different instances.
Results: no distinction in the number of colors, and discriminability is low. Supports the theory.
Interestingly, if we see just 2 colors, the performance doesn't go up. This is despite the fact that in this case we visually could attend to the other-colored-dots. This suggests that we're computing 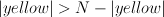 , and not
, and not 
Decomposing complex quantifiers: Evidence from verification
Martin Hackl (Pomona College)
2 goals:
- Studying verification procedures for quantified statements can provide evidence as to how sensitive the theory of NL quantification needs to be to linguistic form of quantified expressions
- Present an experimental paradigm (self-paced counting, or SPC) that recognizes and exploits the fact that incremental processing of complex visual scenes relative to a quantified statement can be uniquely informative, and reflects an incremental nature of verification.
How sensitive to the form that quantifiers assume should the theory of NL quantification be? Many quantifiers are truth-conditionally equivalent:
- More than 6 of the dots
- At least 7 of the dots
- More than half of the 12 dots
- 7 or more of the dots
- More of the dots are blue than there are primes smaller than 17.
But there's some sort of difference between them.
semantic assumptions (GQT):
- determiners denote relations between sets
- NPs and VPs denote sets
- DPs denote ?. Presumably <<e,t>,t>
Issues:
- no reason to choose one meaning over another (truth-conditionally equivalent) meaning
- compositionality of complex quantifiers
Alternative view: decompose complex quantifiers into smaller semantically primitive parts.
Reasonable to believe that 2 complex quantifiers that are denotational equivalent (in the extensional sense) have different semantic representations.
(I didn't take notes for the remainder of this talk)
Computational Linguistics in Support of Linguistic Theory (Invited Plenary Symposium)
Emily M. Bender & D. Terence Langendoen
Slides: http://faculty.washington.edu/ebender/LSA2009.html
(this two-part session a bit preaching to the choir for me. :) )
Some cool sounding tools: EARL, OATS, PHOIBLE, Eraculator, ODIN, WALS, etc. (See slides for references.)
Grammar Matrix: http://www.delph-in.net/matrix
Ellen F. Prince Tribute Symposium
(I didn't take notes for these 3 talks.)
Legal Considerations for Descriptive Linguists and Language Archivists
Paul Newman (Indiana University)
Central characters: the linguist/descriptor, and the archive. Linguists need to know archive rules, and archivists need to understand something about the linguist.
Core actions that you can take with respect to issues:
- what you can do
- what you can prohibit
- what you can authorize
Where do rights & obligations come from? 4 sources.
- Indigenous intellectual property rights (not a legal right).
- Professional and ethical factors (again, not a legal right).
- Contractual agreements
- Copyright
Only the last 2 are legal rights.
Contractual agreements
- Between an archive and a depositor
- Between an archive and a patron/user
- Between depositor and the language community
- Between depositor and funding agencies
If a depositor gives data to an archive, and they agree on a contract, then that's binding. The archive can't come back and say "you're not the copyright holder, so I'll do things not covered in the contract." The contract is independent of the copyright, and the contract parties are bound by the contract.
Note the difference between promises and contracts. Even if you promise to do XYZ, you're not bound to do so unless there's a contract involved.
Copyright
Who owns the copyright for field research?
- Joint ownership: if you work someone to create something, then you are joint owners of the copyright. So are language informants joint copyright owners? Under copyright law, often yes (despite the fact that usually the linguist claims the copyright entirely).
- Work for hire doctrine: if you work with an employee, then the employer owns the copyright. So if your language informant is your employee, then you own the copyright. But just because you pay someone, doesn't mena that they're an employee. E.g., they might be considered a consultant. So it's important to establish exactly what your relationship with the language informant is.
- Transfer of copyright: copyright can be bought, sold, given, inherited, etc.
What is owned?
- You can not copyright facts. You can not copyright data.
- What is copyrightable is the expression of the data.
- Open access vs open use: Open access = free to read, but not necessarily free to use (to incorporate into other work, to translate, or to produce any derivative work)
- Copyright owners can voluntarily forgo rights. E.g., releasing something that you own the copyright for into the public domain. You can also voluntarily forgo some rights under some conditions: licenses.
How long does copyright last?
- Very long (life of author plus 70 years)
- Orphan works are problematic
- How do you find the copyright owner?
http://nflrc.hawaii.edu/ldc/June2007 --- Copyright essentials for linguists (Newman 2007)
Introduction to Access: How to Decide what to Restrict
Heidi Johnson
http://www.ailla.utexas.org/site/lsa_olca09.html
Benefits of archiving
- Preserve recordings of endangered languages
- Facilitate the re-use of materials
- Foster development of oral & written literature
- Make known what documentation there is for a langauge
- Make it possible for data to be cited properly
- All of these benefits require access
Public access vs restricted access.
Public access has some lightweight restrictions. Registration requires agreement with archive terms and conditions. Do not support: automatic harvesting of archived materials; commercial use of archived materials; and creation of derivative works without permission.
Advantages of public access: archive keeps track of the work, continues to provide access 100 years later. Doesn't create barriers in the community. Researcher doesn't have to deal with brokering the language resources.
Restricted access: reasons for restricting access are varied, but the methods are fairly few.
Approaches:
- passwords
- time limit (becomes open access after 10 years). Usually either long enough for researchers to get benefit from the work, or long enough for gossip to become history.
- depositor control: users must ask the depositor for permission. If the depositor fails to respond then the archive takes control of the data.
- Special conditions: specifies how, when, and by whom and for what purposes the resource may be used. These conditions get bundled with the archive, so that 100 years from now the conditions are still known.
What counts as a derivative work?