MALLET: A Machine Learning for Language Toolkit
Mallet is largely undocumented. This page collects information I've gleaned from reading the source code, looking over the gmane.comp.ai.mallet.devel mailing list. Thus, it may not be entirely accurate. Also, it focuses mainly on the parts of the toolkit that I use. I plan to continue updating this page as I learn more about Mallet.
See Also: McCallum 2002
1. Overview
Mallet is a Java toolkit that implements a number of machine learning algorithms. Currently, it includes algorithms for the following tasks:
- Classification: Given an input value, predict its label.
- Sequence Classification: Given an input value consisting of a sequence of elements, predict a corresponding sequence of labels.
- Clustering: Divide a set of values into groups.
- Information Extraction: Given an input value, create a set of database-style records describing specific pieces of information in that value.
- Topic Assignment: Basically a specialized version of clustering.
Each task is defined by a separate package, and each package is basically independent of the others. Within each task, the individual implementations of algorithms are also mostly independent. What all the different algorithms do share is a common set of base types, used to encode and process the data before the machine learning algorithm is applied.
2. Data Types
2.1. Instances: Encode Machine Learning Examples
The Instance class is used to hold a single machine learning "example." The exact definition of an example varies depend on the task, and on the domain it's applied to. For example, in document classification, an instance is a single document; and in word sense disambiguation, an instance is a single word. The Instance class is intentionally quite generic. It defines four attributes: data, target, name, and source. Of these, only the first two (data and target) are typically used by the machine learning algorithms; the name and source are mainly used for tracking, debugging, and error analysis.
- target
- The target is used for supervised machine learning tasks, and contains the value we wish to predict for each example. For example, in word sense disambiguation, the target would contain the word sense; and in part of speech tagging, it would contain the part of speech sequence for a single sentence. The target attribute is not used for unsupervised tasks, such as clustering.
- data
- The data attribute defines the (input) value of the example. This value can be encoded using any object type. Typically, an instance will be created with a data attribute that just names the location of its input (e.g., filename) or gives the input in a raw form; and then the instance will be modified by a series of Pipes, eventually ending up in the form suitable for input to the desired machine learning algorithm, such as a FeatureVector (for classification tasks) or an array of FeatureVectors (for sequence learning tasks).
- name
- A short human-readable name specifying the source of the instance. Typically, the name is a string. This is used, e.g., for error analysis.
- source
- Human readable information about the data content of the instance, such as a string containing the instance's text.
The InstanceList class is used to hold a list of machine learning examples. InstanceLists are typically used to hold data sets (such as training data or test data) for machine learning algorithms. The InstanceList class defines a number of utility methods, including methods that divide a corpus into different subsets, e.g., into a training set and a testing set, or into cross-validation sets; and a method to find the frequency of each target value.
In addition to holding a list of Instances, the InstanceList contains several additional attributes. Two of these, the data alphabet and the target alphabet, are used to track identifiers used inside the instances' data and target values, respectively. See the next section for more details. The InstanceList also defines an optional attribute that associates a floating-point weight with each instance; and two optional attributes that can be used to indicate which features of the instance's data value should be used by machine learning algorithms. We'll return to these optional features later.
2.2. Alphabets: Assign Unique Integer Ids to Objects
If you're going to be working with Mallet, it's important that you understand what alphabets are, and how Mallet uses them. An alphabet is basically just a bi-directional mapping between objects (called entries) and integer ids. The integer ids start at zero, and are assigned consecutively. Mallet uses alphabets extensively, so that it can represent values such as labels and features using ints rather than Objects.
The primary reason why alphabets are used in mallet is to allow mappings from entries to other values to be represented using vectors. In particular, you can think of an alphabet as a vector defining an ordering over entries:
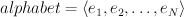
Given this ordering of entries, we can represent a mapping between entries and some
other set of values  by defining a vector of those values, with the value at
position
by defining a vector of those values, with the value at
position 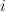 corresponding to the entry at position :
corresponding to the entry at position :
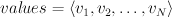
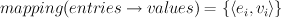
This vector representation of mappings is convenient for many machine learning algorithms, which often perform matrix operations on values that are associated with an alphabet's entries. It is also a more compact encoding of the mapping than most alternatives (such as a HashMap) in the case where we expect to associate many different sets of values with the same set of entries; and once we've converted the entries to identifiers, mapping from those identifiers to the corresponding values is extremely fast.
The most important thing to keep in mind when working with alphabets is the following rule:
The identifiers generated by alphabets are supposed to uniquely identify entries; but if you use two different Alphabet objects for the same set of entries, you'll end up with two incompatible identifiers for the same entry. For example, a common mistake is to define one set of pre-processing transformers (called pipes) for training; but then to create a new set of pre-processing transformers when testing. Even if these transformers perform the same functions, their outputs will be incompatible because internally each uses its own alphabets. The solution is to save the transformers, and re-use them when testing.
Alphabets are implemented using the Alphabet class. Alphabets are monotonic: once an object/id pair has been added, it may not be removed.
2.3. Labels
- label
- An object (typically a string) used to represent a label.
- LabelAlphabet : label
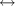 label_id
label_id - An alphabet used to assign identifiers to label. It differs from a normal Alphabet in that it automatically creates a Label wrapper for each label, which directly records the identifier.
- Label : label, label_id
A wrapper for a label that records the label's identifier. Label objects are automatically created by the LabelAlphabet whenever a new label is added to the alphabet. As far as I can tell, the use of a wrapper class is a convenience, to avoid having to use the LabelAlphabet to look up the identifier for a label. In general, very little code handles the unwrapped label values; almost everything uses the Label wrappers. Unless explicitly specified otherwise, all mention of labels will refer to the wrapper class, not the underlying value.
Labels also implement the Labeling interface, basically defining a distribution that assigns a score of 1 to this and 0 to anything else. I'm not sure why this is used -- and if it is useful, then it really seems like there should be a separate class that defines a labeling with a score of 1 for the label, rather than extending the Label class itself in this way.
The Labels class defines an array of Labels.
- Labeling : Alphabet(Labels), mapping(Labels
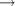 score)
score) - (Interface.) A distribution of scores over labels. This assumes a fixed alphabet of labels. You can ask for the score or rank of a label, or for the label with a given score or rank.
- LabelVector : Alphabet(Labels), mapping(Label score)
- An implementation of the Labeling interface. The scores are maintained in sorted order, from highest to lowest. For purely implementation reasons, this class is derived from RankedFeatureVector -- but it is not a feature vector.
- LabelSequence : Alphabet(Labels), list(label_id)
- A sequence of labels, represented using a list of label ids and an alphabet. A typical use is as the target for an instance in a sequence learning task. For purely implementation reasons, this class is derived from FeatureSequence -- but it contains labels, not features.
2.4. Features
- Feature
- A feature can be encoded using any type -- the value of a feature is only used to check if two features are equal. Typically, features are Strings.
- Set of features
- The set of features used to describe input values is represented using an Alphabet, typically containing string names. This mapping gives us a feature id for each feature. The rest of the types described in this section all take an Alphabet mapping features to ids as an argument to their constructors.
- FeatureSelection : Alphabet(features), set(feature_id)
- A set of features. (I.e., a subset of the objects defined in a given Alphabet) This is not just used for features -- it is used for labels sometimes too.
- FeatureVector : Alphabet(features), mapping(feature_id value)
- A mapping from features to binary or floating point values. Internally, FeatureVector uses a sparse representation that lists the ids of features.
- RankedFeatureVector : Alphabet(features), mapping(feature_id value)
- A FeatureVector that keeps the list of feature ids (and corresponding list
of values) sorted in descending value order. I.e.,
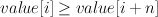 for any
for any 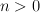 .
.
- FeatureSequence : Alphabet(features), list(feature_id)
- A list of features, represented using a list of feature ids and an alphabet. This list may contain duplicates. Although its name suggests otherwise, this class is not just used to record features. E.g., it is also used to store output the output value for sequence labeling tasks.
- FeatureConjuction : Alphabet(features), list(feature_id), list(is_negated)
- A binary formula over features. E.g.,
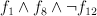 . This
is used to define new features that are derived from base features.
. This
is used to define new features that are derived from base features.
2.6. Container Types
Mallet defines a number of generic container types. These types are not specialized for machine learning per se.
- Sequence
- (Interface). A simple sequence interface that only requires a length and an accessor. It's not clear why mallet needs to define its own sequence interface, rather than using the standard collection hierarchy.
- ArraySequence
- An implementation of Sequence that's backed by an array of objects.
- Matrix, ConstantMatrix
- (Interfaces.) Standard interfaces for matrices of floating point numbers. Entries in the matrix can be accessed using a series of indices (one for each dimension), or a single 'collapsed' index.
- SparseVector
- A sparsely encoded array of booleans or floating point numbers.
3. Sequence Classification
In Mallet, sequence classification is performed using weighted transducers. In particular, a trained sequence classifier model is encoded as a weighted FST that maps input sequences 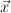 to output sequences
to output sequences 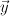 , and assigns a cost to each mapping. (These costs can then be converted to probability estimates.) Each transition in the transducer is assigned a single cost; and the cost of a mapping is computed by summing the costs of all transitions used to perform the mapping. The number of transitions that a weighted transducer muist contain is typically very large, corresponding to the number of values
, and assigns a cost to each mapping. (These costs can then be converted to probability estimates.) Each transition in the transducer is assigned a single cost; and the cost of a mapping is computed by summing the costs of all transitions used to perform the mapping. The number of transitions that a weighted transducer muist contain is typically very large, corresponding to the number of values 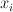 can take -- if is a FeatureVector with
can take -- if is a FeatureVector with 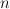 features, then can have
features, then can have 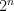 possible values. Therefore, transitions are not explicitly represented, but are generated on an as-needed basis.
possible values. Therefore, transitions are not explicitly represented, but are generated on an as-needed basis.
3.1. Transducers
All transducers are encoded using subclasses of the Transducer class, defined in the mallet.base.fst package. This class defines the basic transducer data structure along with a large collection of subclasses that can be used to compute interesting values from the transducer. The basic methods to access a transducer as a data structure are:
- int numStates()
- Return the number of states in this transducer.
- State getState(index)
- Return the state at the given index.
- Iterator initialStateIterator
- Return an iterator over States that generates all initial states. This appears to me to be a convenience function -- presumably you could get the same set of states by calling getState() to get each state, and checking for those that are initial states (i.e., whose "initial cost" is finite).
3.2. States
States are represented using the Transducer.State class. Each state is identified by a name and an index; the index should obey the following invariant:
someTransducer.getState(i).getIndex() == i
Each state also defines two costs: initial cost, the cost of starting a mapping with the FST in this state; and final cost, the cost of finishing a mapping with the FST in this state. Finally, each state defines a set of methods that can be used to iterate over the outgoing transitions from that state. These methods may optionally be given an input sequence and position, and/or an output sequence and position, which will be used to limit the set of transitions returned -- in particular, the transitionIterator will only return transitions that are consistent with that input and/or output. Without this, the number of transitions returned might need to be impractically large, as mentioned above.
3.3. Transitions
Transitions are not explicitly represented by any data class; instead, information about each transition can be obtained, one transition at a time, using specialized iterators of the Transducer.TransitionIterator class. This iterator generates states when you iterate over it; but after each state is generated, the iterator can be queried for information about a transition whose destination is the generated state. In particular, TransitionIterators provide the following information:
- Object getInput()
- The input value for this transition -- typically a FeatureVector.
- Object getOutput()
- The output value for this transition -- typically a Label.
- double getCost()
- The cost of the transition.
- State getSourceState()
- The source state in the FST for this transition -- this will be the state that returned the TransitionIterator
- State getDestinationState()
- The destination state in the FST for this transition -- this will be the State that was just generated by the iterator's next() method.
In order to make displaying transitions easier, TransitionIterator also implements the method describeTransition(cutoff), where cutoff is used to decide how verbosely the transition's input value should be described.
3.4. Prediction: Transducer.ViterbiPath and Friends
Once we have trained a model (i.e., a Transducer) for a sequence classification task, we can use it to predict the most likely output value for new input values. The Transducer class defines a number of methods that can be used for this task, but the simplest is viterbiPath. Given an input sequence, and optionally an output sequence, this method will construct a new object (with class Transducer.ViterbiPath) that uses the Viterbi algorithm to encode the most likely path through the transducer that is consistent with the given input (and output, if supplied). The most useful method in the Transducer.ViterbiPath class is output(), which returns the highest scoring output sequence (as a Sequence of Label``s). The ``getCost() method returns the score of the label sequence returned by output(). The tokenAccuracy(referenceOutput) method compares the viterbi output to the given reference output, and returns the percent of tokens that are correctly labeled.
3.5. Summing Over Paths: Transducer.Lattice and Friends
The Transducer.Lattice class is a compact representation of all possible paths through the transducer for a single input value. It can be used to calculate a number of quantities that can be useful to machine learning algorithms, such as the total cost of all paths, and the total cost of all paths that go through a given state at a given time.