| Tags: |
|---|
Probabilistic CFG with Latent Annotations (PCFG-LA)
Matsuzaki, Miyao, & Tsujii examine the possibility of automating the task of choosing an optimal problem decomposition. They restrict their attention to the class of problem decompositions that is formed by augmenting PCFG nodes with discrete feature values (or latent annotations). These decompositions effectively transform the canonical parse tree by subdividing the existing phrase types (NP, PP, etc) into sub-types.
This transformation differs from most of the transformations discussed
so far in that it does not define a one-to-one mapping between
canonical values and transformed values. In particular, if 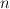 discrete feature values are used to augment canonical trees, then a
canonical tree with
discrete feature values are used to augment canonical trees, then a
canonical tree with 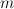 nonterminal nodes corresponds to
nonterminal nodes corresponds to 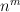 different augmented trees (one for each possible assignment of feature
values to nodes). As a result, applying standard parsing algorithms
to the augmented PCFG will generate the most likely annotated tree;
but this does not necessarily correspond to the most likely
unannotated (canonical) tree. Matsuzaki, Miyao, & Tsujii therefore
explore the use of three different variants on the CKY parsing
algorithm which approximate the search for the best unannotated tree.
different augmented trees (one for each possible assignment of feature
values to nodes). As a result, applying standard parsing algorithms
to the augmented PCFG will generate the most likely annotated tree;
but this does not necessarily correspond to the most likely
unannotated (canonical) tree. Matsuzaki, Miyao, & Tsujii therefore
explore the use of three different variants on the CKY parsing
algorithm which approximate the search for the best unannotated tree.
Starting with a PCFG grammar and a fixed set of feature values, Matsuzaki, Miyao, & Tsujii apply the Expectation Maximization algorithm to iteratively improve upon the PCFG's transition probabilities. As a result, the PCFG automatically learns to make use of the feature values in such a way that the likelihood of the training corpus is maximized. Using their approximate-best parsing algorithms on the PCFG generated by EM, Matsuzaki, Miyao, & Tsujii's parser achieves performance comparable to unlexicalized parsers that make use of hand-crafted problem decompositions.