| Date: | June 1-5, 2009 |
|---|
NAACL 2009
Shared Logistic Normal Distributions for Soft Parameter Tying in Unsupervised Grammar Induction
Shay Cohen and Noah A. Smith
Bayesian methods:
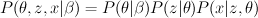
- theta = parameters
- z = hidden structure
- x = evidence
- beta = hyperparameters
Assume an underlying generative distribution
- Work in a parametric space.
- Use a logistic normal distribution for prior (not derichlet)
Use the prior: - to tie parameters in the grammar - to encode linguistic information - Used over a family of multinomials - Used for multilingual learning
Encoding prior knowledge: let the model know which part of speech tags are related to one another. (E.g., NN, NNS, NNP get grouped)
Logistic normal prior lets us tie between parameters that are within the same multinomial. But we can't tie between parameters in different multinomials. So instead of learning each multinomial on its now, we learn them in adjoined normal spaces.
Treat the entire parameter space as a single unit, with a single prior, rather than dividing it up.