| Tags: |
|---|
Can Subcategorization Help a Statistical Dependency Parser?
Zeman presents a statistical dependency parser for Czech, and shows that adding features based on verb subcategorization improves performance. Czech has a rich morphological case system, and relatively free word order.
The baseline system is a statistical dependency parser that predicts dependencies between words based on their morphological category, distance, and direction. In addition, several constraints, such as "projectivity" are imposed to eliminate incorrect parses.
They first extend this baseline system by lexicalizing prepositions, conjunctions, the verb "to be", and (non-adjectival) adverbs. They also adjust the probabilities of dependencies involving verbs, by summing their nonlexicalized and lexicalized probabilities. (Note: the result isn't a real probability distribution; but it increases performance.) These changes give almost no change in performance (77.0 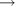 77.1).
77.1).
They then use a subcategorization dictionary to give preferences to "subcategorized dependencies," or dependencies that are listed in the dictionary. (The dictionary specifies case marking for the subcategorized dependencies.) This increases the performance by about 1.5 (77.1 78.7).
All performance scores are measured as accuracy over dependencies.
Bibtex
@InProceedings{zeman2002,
author = {Daniel Zeman},
title = {Can Subcategorization Help a Statistical Dependency Parser?},
booktitle = {Proceedings of the 19th International Conference on Computational Linguistics},
year = 2002,
address = {Taibei, Taiwan}
}